
The last many months I’ve been struggling with having a boot up time of a good 10 – 15 minutes with Manjaro KDE. As this is a rolling distro, my configs are many years old as I don’t do refresh installs every major release, and there have also been many modbus writes made to the kernel for various hardware I’ve bought over the years. So, the login screen would appear fairly quickly, but the KDE desktop only started responding efficiently after 15 minutes or so (after I’d gone to make a cup of coffee).
I won’t go through all the fixes I’ve tried as there are many, including delaying auto start apps, the usual cleaning of cache files, build files, trying ZRAM, etc.
Some really useful commands that helped me were:
* systemd-analyze blame – to see what affects the desktop startup times.
* systemd-analyze blame –user – this was a new one today I tried and it did indicate the app Keybase was causing long delays, so I did remove that app today.
* journalctl -b -p err – this is a good one to show systemd boot related issues, and it for example showed if my USB headphones adaptor was plugged in without the headphones connected, it spend time trying to find them.
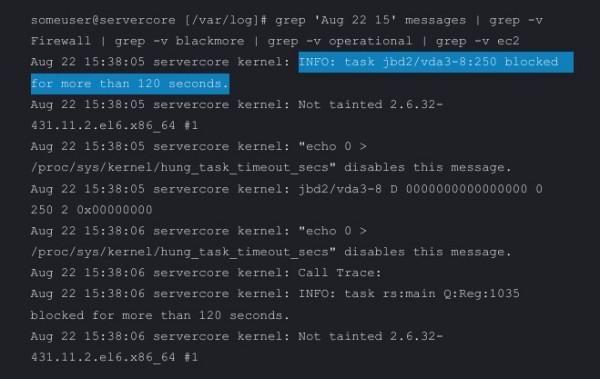
I had really eliminated most issues, but one thing remaining were a few kernel messages moaning about a task that had been blocked for more than 122 seconds. The task was sometimes different, and although speeds were OK after the boot process finished, I’d see some fresh errors reported about tasks hanging for over 122 seconds, such as ‘kernel: INFO: task APEX_CONTEXT_WO:2401 blocked for more than 122 seconds’.
But today was a GOOD day as my long-lost parcel turned up at the SA Post Office (no notification of course sent to me), so I thought I’d spin the wheel of fortune one more time, and I found the linked article below.
So, after trying this out, the reboot was much quicker. The desktop was responding within a minute after login, and I even noticed that opening apps, as well as browser tabs, was also a bit snappier. I’ve done two reboots now, and it really does seem to have sorted it out.
The explanation, especially for those who have a system with a lot of RAM (I have 32 GB of RAM): This is a known bug. By default, Linux uses up to 40% of the available memory for file system caching. After this mark has been reached, the file system flushes all outstanding data to disk, causing all following IOs going synchronous. For flushing out this data to disk this there is a time limit of 120 seconds by default. In the case here, the IO subsystem is not fast enough to flush the data within 120 seconds. This especially happens on systems with a lot of memory.
Essentially the system is waiting way too long when some tasks don’t respond, so it seems to need a quicker break out, and systems with more RAM have not hit the 40% threshold. It essentially involved editing the sysctl.conf file and adding two lines to clean up these wait states:
sudo nano/etc/sysctl.conf
Add these two lines at the end of that file, save, and reboot:
vm.dirty_background_ratio = 5 vm.dirty_ratio = 10
But yes, I’m not sure why Linux does not lower that flush threshold if it sees the RAM is more. Maybe it did and my older install did not get some updated config files.
See https://www.blackmoreops.com/2014/09/22/linux-kernel-panic-issue-fix-hung_task_timeout_secs-blocked-120-seconds-problem/
Still some blocked tasks appearing now such as ‘kernel: INFO: task APEX_CONTEXT_WO:2269 blocked for more than 122 seconds’ and this solution at https://forum.manjaro.org/t/xorg-and-kworker-blocked-for-more-than-122-seconds/126006/6 got rid of this specific one. I did test it first by editing the Grub line during bootup, before adding the `ibt=off`command into the Grub file.